Jenkins – Pipeline Retry Strategy Using Self-Rebuild and Shared Library
Overview
In modern CI/CD environments, especially those with strong dependencies on external services (APIs, networks, third-party systems), transient failures are inevitable. Retrying failed pipelines becomes essential to improve reliability and reduce manual intervention.
This article presents a robust and production-ready retry strategy for Jenkins pipelines, based on:
- Self-triggered pipeline re-execution
- Parameter propagation across builds
- Controlled retry logic via Shared Library
- Compatibility with dynamic parameters (including Active Choices)
The solution ensures deterministic retries while preserving execution context.
Quick Summary
Advantages
- Fully automated retry mechanism (no manual intervention)
- Preserves all parameters across retries
- Deterministic and reproducible executions
- Stateless design (no dependency on previous workspace)
- Works with dynamic parameters (Active Choices, Reactive)
- Centralized logic via Shared Library
- Clear and traceable build history (each retry = new build)
Disadvantages
- Re-executes the entire pipeline (including successful stages)
- No re-evaluation of dynamic parameters (Active Choices)
- Requires explicit parameter propagation logic
- Potential for overlapping builds if concurrency is not controlled
- Slight delay overhead (sleep + scheduling)
When This Approach Is Useful
This retry strategy is particularly beneficial in scenarios such as:
External Dependency Instability
- APIs with intermittent failures
- Third-party services with rate limits or timeouts
- Cloud provider transient issues
Network-Sensitive Pipelines
- Artifact downloads (S3, Nexus, Artifactory)
- Git operations under unstable connectivity
- Remote deployments over SSH
Flaky Test Environments
- Integration tests with external systems
- End-to-end tests with shared environments
- Race conditions in distributed systems
Long Pipelines Where Manual Retry Is Costly
- Complex CI/CD pipelines
- Multi-stage deployments
- Pipelines triggered overnight or unattended
Stateless Build Environments
- Ephemeral agents (Kubernetes, cloud runners)
- Non-persistent workspaces
- Immutable infrastructure setups
Core Concept
Instead of retrying individual steps or stages, this approach:
Re-executes the entire pipeline as a new build, preserving the original parameters.
This is functionally equivalent to a manual “Build Again”, but automated, controlled, and consistent.
Architecture
The solution is composed of two main parts:
- A Shared Library function (
retryPipeline) - A pipeline that invokes it in
post { failure }
Shared Library Implementation
def call(Map config = [:]) {
int maxRetries = config.get('maxRetries', 3)
int baseDelaySeconds = config.get('baseDelaySeconds', 60)
int currentRetry = 0
if (params.containsKey('RETRY_COUNT')) {
currentRetry = params.RETRY_COUNT.toString().toInteger()
}
// Avoid retry on manual abort
if (currentBuild.rawBuild.getResult().toString() == 'ABORTED') {
echo "Build was aborted. Skipping retry."
return
}
echo "Internal retry count: ${currentRetry}"
if (currentRetry < maxRetries) {
int nextRetry = currentRetry + 1
int delaySeconds = baseDelaySeconds
currentBuild.displayName = "#${env.BUILD_NUMBER} (retry ${nextRetry})"
echo "Retry ${nextRetry}/${maxRetries} in ${delaySeconds} seconds..."
sleep time: delaySeconds, unit: 'SECONDS'
// Propagate parameters
def currentParams = params
.findAll { key, value -> key != 'RETRY_COUNT' }
.collect { key, value ->
if (value instanceof Boolean) {
return booleanParam(name: key, value: value)
} else {
return string(name: key, value: value.toString())
}
}
currentParams += string(name: 'RETRY_COUNT', value: "${nextRetry}")
build job: env.JOB_NAME,
parameters: currentParams,
wait: false
} else {
echo "Max retries reached (${maxRetries}). Not retrying."
}
}Example Pipeline
@Library('devopsdb-global-lib') _
def default_maxRetries = 3
def default_baseDelaySeconds = 20
properties([
parameters([
string(name: 'ENV', defaultValue: 'dev'),
booleanParam(name: 'RUN_TESTS', defaultValue: true),
choice(name: 'REGION', choices: ['eu-central-1', 'eu-west-1', 'eu-north-1']),
[$class: 'CascadeChoiceParameter',
name: 'SERVICE',
choiceType: 'PT_SINGLE_SELECT',
script: [
$class: 'GroovyScript',
script: [script: "return ['payments','billing','orders']", sandbox: true],
fallbackScript: [script: "return ['fallback']", sandbox: true]
]
],
[$class: 'CascadeChoiceParameter',
name: 'ENDPOINT',
choiceType: 'PT_SINGLE_SELECT',
referencedParameters: 'REGION',
script: [
$class: 'GroovyScript',
script: [script: """
if (REGION == 'eu-central-1') {
return ['api.prod.local', 'api2.prod.local']
} else {
return ['api.dev.local', 'api2.dev.local']
}
""", sandbox: true],
fallbackScript: [script: "return ['fallback-endpoint']", sandbox: true]
]
]
])
])
pipeline {
agent any
stages {
stage('Main') {
steps {
script {
echo "=== PARAMETERS PRINTS ==="
params.each { k, v ->
echo "${k} = ${v} (type=${v?.getClass()?.getName()})"
}
if (params.RETRY_COUNT.toInteger() < 2) {
error "Failing on purpose (simulate flaky dependency)"
}
}
}
}
}
post {
failure {
retryPipeline(
maxRetries: default_maxRetries,
baseDelaySeconds: default_baseDelaySeconds
)
}
}
}Source: https://github.com/faustobranco/devops-db/tree/master/infrastructure/pipelines/retry-pipeline
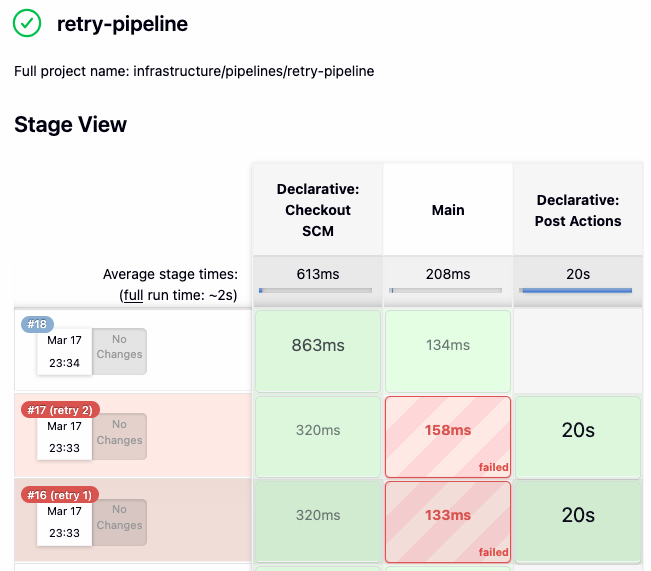
How the Retry Mechanism Works
- Initial build starts with
RETRY_COUNT = 0 - On failure,
post { failure }triggers the retry - Shared Library:
- increments retry counter
- waits (
sleep) - triggers a new build
- All parameters are copied and passed forward
- New build runs from scratch
Parameter Propagation Explained
Jenkins does not automatically pass parameters between builds.
This solution explicitly:
- Reads current
params - Recreates them (
string,booleanParam) - Overrides
RETRY_COUNT - Passes them to the next build
This guarantees:
- identical inputs
- no fallback to defaults
- consistent execution
Design Philosophy
A retry must reproduce the same execution context, not recompute it.
This means:
- No dynamic parameter recalculation
- No dependency on UI logic
- No reuse of previous workspace
Conclusion
This retry strategy provides a robust and production-ready approach for handling transient failures in Jenkins pipelines.
By prioritizing:
- consistency
- reproducibility
- simplicity
it ensures that retries behave exactly as expected — reliable, predictable, and fully automated.
