Jenkins – Designing a Modular Jenkins Pipeline Framework for Scalable CI/CD
Introduction
As CI/CD pipelines grow alongside modern microservice architectures, Jenkins pipelines often become increasingly complex. What starts as a simple Jenkinsfile quickly evolves into a large script containing build logic, test execution, deployment orchestration, infrastructure configuration, and environment-specific rules.
Over time, this leads to several common problems:
- duplicated logic across pipelines
- pipelines that are difficult to maintain
- limited reuse between services
- difficulty scaling CI/CD workflows
To address these challenges, a modular Jenkins pipeline framework was developed with the goal of transforming pipelines from monolithic scripts into configurable workflows composed of reusable modules.
Instead of embedding the entire logic in a Jenkinsfile, the pipeline becomes a configuration layer, while reusable modules encapsulate execution logic.
This approach enables:
- reusable pipeline components
- dynamic pipeline composition
- parallel execution of stages
- flexible infrastructure targeting
- centralized CI/CD logic
- eliminate duplicated pipeline logic
- allow pipelines to be defined declaratively through configuration
- allow multiple executions of the same module with different parameters
- integrate seamlessly with Jenkins parameters
- support heterogeneous execution environments (Kubernetes, VMs, dedicated agents)
Full source code
The complete source code used in this article is available on our GitHub:
https://github.com/faustobranco/devops-db/tree/master/knowledge-base/jenkins/framework
The Core Idea: Pipelines as Configuration
The fundamental design principle of this framework is simple:
Pipelines describe what should happen, while modules define how it happens.
Instead of writing procedural pipeline code, engineers define a configuration structure like this:
stages: [
[stage: "configure", service: "devops"],
[
[stage: "build_image", service: "api"],
[stage: "build_image", service: "worker"],
[stage: "build_image", service: "scheduler"]
],
[stage: "test", service: "devops"],
[
[stage: "deploy", service: "api"],
[stage: "deploy", service: "worker"]
]
]This configuration defines:
- which modules will run
- the order of execution
- which stages run in parallel
- the parameters passed to each module
The pipeline framework reads this configuration and dynamically executes the corresponding modules.
This makes pipelines significantly easier to read, modify, and reuse.
Framework Architecture
The framework is composed of three main layers.

Each layer has a clearly defined responsibility.
Jenkinsfile: The Pipeline Entry Point
The Jenkinsfile serves as the pipeline entry point and contains only minimal orchestration logic.
Its primary responsibilities are:
- loading the pipeline framework
- defining pipeline parameters
- providing the stage configuration
Because most of the execution logic lives in modules, the Jenkinsfile remains extremely concise.
This dramatically improves maintainability and readability.
Pipeline Framework: The Orchestrator
The framework acts as the execution engine for the pipeline.
Its responsibilities include:
- discovering available modules
- loading modules dynamically
- orchestrating stage execution
- handling parallel stages
- merging global and stage-specific configuration
- selecting execution environments (nodes or containers)
One of the most powerful aspects of the framework is dynamic module discovery.
Modules are automatically loaded from the modules directory:
def files = pipeline.sh(
script: "ls modules/*.groovy",
returnStdout: true
).trim().split("\n")
files.each { file ->
def moduleName = file.tokenize("/").last().replace(".groovy","")
modules[moduleName] = load file
}
This means that new pipeline capabilities can be added simply by creating a new module file.
No changes to the framework itself are required.
Modules: Reusable Execution Units
Modules encapsulate individual pipeline tasks.
Each module implements a simple interface:
def run(Map config)
The configuration map provides:
- pipeline context
- stage parameters
- Jenkins environment variables
- shared utilities
This interface ensures consistency across modules while allowing complete flexibility in implementation.
Example Modules
Configure Module
The configure module prepares the pipeline execution environment.
Typical responsibilities include:
- determining the current Git revision
- preparing workspace directories
- initializing resources required by later stages
Example functionality:
- retrieving the current commit version
- validating workspace structure
- preparing artifact directories
This module ensures the pipeline starts from a known and reproducible state.
Build Image Module
The build_image module builds container images for microservices.
Example usage:
build_image(api)
build_image(worker)
build_image(scheduler)
Each execution of the module receives different parameters, allowing the same build logic to be reused across multiple services.
This pattern significantly reduces code duplication.
Test Module
The test module executes automated validation steps such as:
- unit tests
- integration tests
- repository validation
This stage ensures that services meet quality standards before deployment.
Deploy Module
The deploy module is responsible for deploying services to the target environment.
Typical responsibilities include:
- triggering Helm deployments
- updating container versions
- validating environment configuration
It can also access Jenkins parameters, enabling dynamic deployments based on runtime inputs.
Parallel Stage Execution
One of the major benefits of the framework is built-in support for parallel execution.
If a stage definition contains a list of stages, the framework interprets them as parallel tasks.
Example:
[
build_image(api)
build_image(worker)
build_image(scheduler)
]
These stages run simultaneously, dramatically reducing pipeline execution time.
This is particularly effective in microservice architectures where services can be built independently.
Multiple Executions of the Same Module
The framework allows a module to be executed multiple times with different parameters.
For example:
build_image(api)
build_image(worker)
build_image(scheduler)
All executions use the same module code but receive different configurations.
This pattern is extremely powerful because it combines:
- reuse
- flexibility
- configuration-driven execution
Supporting Multiple Execution Environments
Modern CI/CD environments often require pipelines to run across different infrastructures.
For example:
- Kubernetes agents
- dedicated build servers
- Docker hosts
- specialized build nodes
The framework supports this by allowing stages to specify execution contexts.
Example configuration:
build_image:
node: docker
test:
container: container-1
The framework dynamically routes execution to the correct environment.
This allows a single pipeline to mix:
- containerized execution
- Kubernetes agents
- dedicated VM nodes
without changing module logic.
Dynamic Jenkins Parameters
The framework integrates seamlessly with Jenkins parameters.
For example:
- PROJECT
- APPLICATION_VERSION
- ENVIRONMENT
These parameters can be passed into modules through the configuration map, allowing pipelines to adapt dynamically at runtime.
This enables use cases such as:
- selecting application versions
- choosing deployment environments
- dynamically configuring pipelines based on user input.
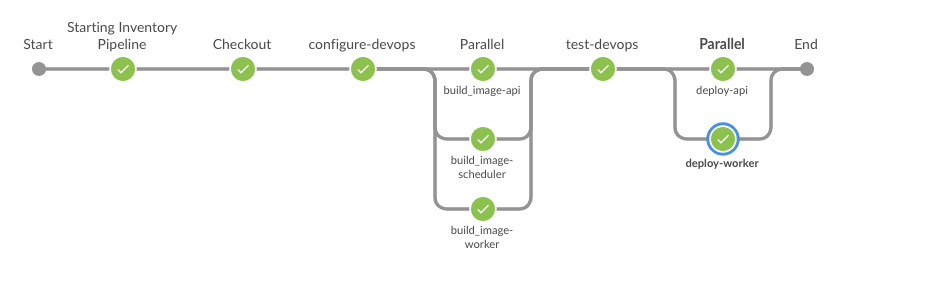
The Inventory Pipeline: A Complete Example
The Inventory pipeline is currently the most advanced pipeline using this framework.
Its workflow looks like this:

This structure reflects a realistic microservice CI/CD workflow:
- prepare the environment
- build multiple services in parallel
- run validation tests
- deploy services
The pipeline demonstrates how complex workflows can be represented through simple configuration.
Key Benefits of the Framework
Strong Reusability
Modules can be reused across many pipelines.
A single module may support dozens of services.
Reduced Pipeline Complexity
Jenkinsfiles become declarative configurations rather than procedural scripts.
Easy Extensibility
Adding new functionality requires only creating a new module file.
Consistency Across Projects
All services share the same CI/CD architecture.
Faster Pipeline Execution
Parallel stages dramatically reduce pipeline runtime.
Infrastructure Flexibility
Stages can run across multiple environments without changing module code.
Conclusion
This modular pipeline framework transforms Jenkins pipelines from monolithic scripts into configurable, reusable, and scalable CI/CD workflows.
By separating orchestration from execution and relying on dynamic module loading, the framework achieves:
- strong modularity
- high reusability
- clean pipeline definitions
- infrastructure flexibility
The Inventory pipeline demonstrates how this architecture can support complex microservice workflows while remaining maintainable and easy to evolve.
As CI/CD environments continue to scale, modular pipeline architectures like this provide a powerful foundation for sustainable DevOps practices.
